文档统计(Statistics)
为文档创建新的统计变量。
输入
- 语料库: 文件集。
输出
- 语料库: 带有附加属性的语料库。
功能
文档统计(Statistics)是一个特征构造小部件,它可以为语料库添加简单的文档统计数据。它同时支持标准的统计措施和用户定义的变量。
界面
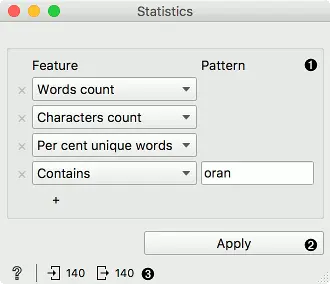
- 添加或删除特征。可以用下面的
+号添加功能。可以用左侧的×号来删除。特征选项有:- 词数量:文档中的词数。
- 字母数:文档中的字符数。
- n-grams珊瑚粮:n-grams的数量。在文本预处理中定义n-grams,否则将只报告unigrams。
- 平均词长:字符数与词数之比。
- 标点数:标点符号的数量
- 大写字母数:大写字母数
- 元音数:元音的数量,默认是 “a, e, i, o, u”,但用户可以自己添加。。
- 辅音数:辅音的数量,默认值是给定的,但用户可以调整。
- 单个词占比: 唯一词的比例(类型/标记)。
- 起始于:一个词以指定序列开始的次数。
- 结束于:一个词以指定序列结束的次数。
- 包含:词中指定序列的次数。
- 正则表达式:所提供的正则表达式与标记匹配的次数。
- POS 标签:统计指定的POS标签。需要文本预处理中的 POS 标记标记。英语的Tree POS 标签列表可以在这里找到。
- 按Apply键,输出具有新特征的语料。
- 状态行,左边是帮助,右边是输入和输出。
示例
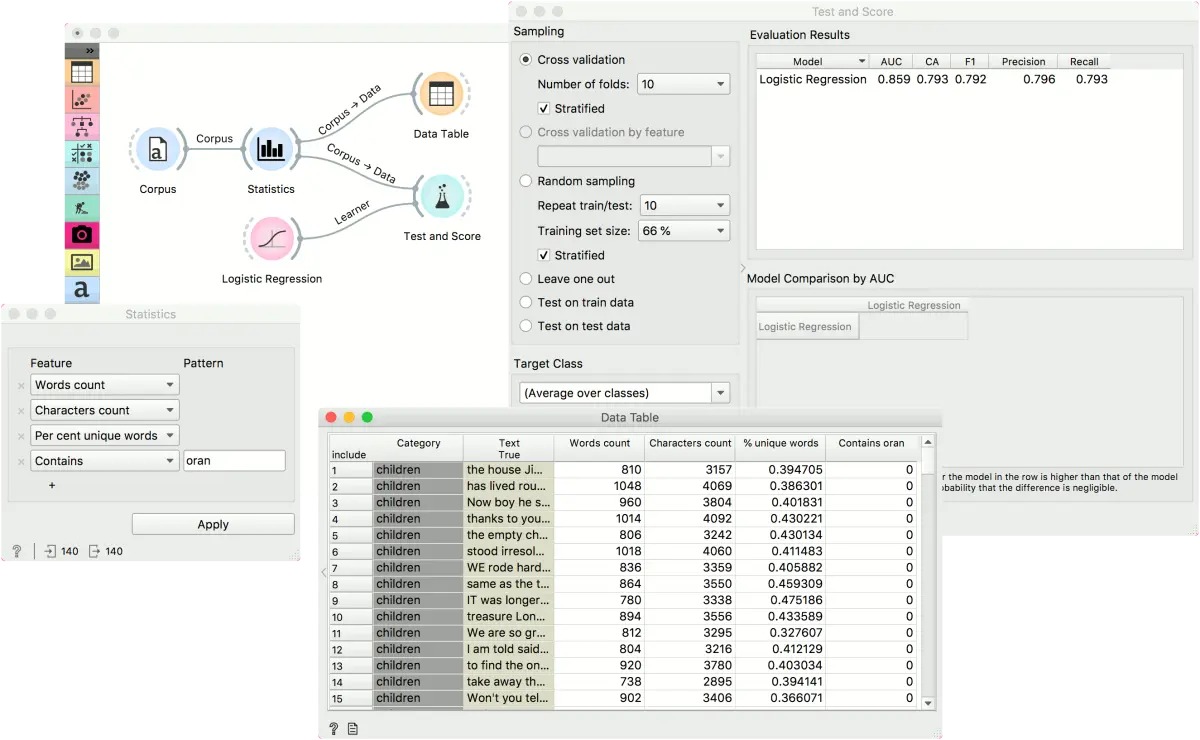
这个简单的例子展示文档统计(Statistics)小组件是如何工作的。由于它是一个基本的特征构造小部件,所以可以直接在语料库之后使用。我们添加了几个特征,分别是字数、字符数、唯一词的百分比和包含’oran’的词数。我们可以在数据表中观察到带有附加列的表格。
我们也可以用测试与评分来使用统计学的输出进行预测建模。然而,通常情况下,我们只会使用文档统计(Statistics)小组件来增强词袋小工具的特征。有些特征需要 POS 标记,可以使用 文本预处理 小部件创建。
反馈问题
文档有问题? 或者有其他意见和建议? 请在本文档的 Github 仓库直接反馈
点我反馈进入反馈页面不知道如何反馈, 请点击这里